Load the cleaned dataset generated during the EDA phase. Confirm shape, types, and integrity of the data before modeling.
Import Statements
Includes core data science libraries (pandas, NumPy, matplotlib, seaborn), model tools (XGBoost, Optuna), and metrics. Also sets pandas display and visualization options.
Code
import osimport warningsfrom math import sqrtimport numpy as npimport pandas as pdfrom pandas.tseries.offsets import Weekimport matplotlib.pyplot as pltimport seaborn as snsimport joblibimport shapfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.inspection import permutation_importancefrom sklearn.metrics import mean_squared_error, mean_absolute_error, r2_scorefrom xgboost import XGBRegressorimport xgboost as xgbfrom xgboost.callback import EarlyStoppingfrom lightgbm import LGBMRegressorfrom catboost import CatBoostRegressorimport optunafrom optuna.samplers import TPESamplerimport optuna.visualization as viswarnings.filterwarnings("ignore")sns.set(style="whitegrid")pd.set_option("display.max_columns", None)pd.set_option("display.width", 0)pd.set_option("display.float_format", "{:,.2f}".format)shap.initjs()
Load Data
Reads in the cleaned CSV generated from the EDA notebook. Ensures the ‘Date’ column is parsed as a datetime object.
Code
# Ensure date remains a datetime objectdf = pd.read_csv("../data/data_processed.csv", parse_dates=["Date"]) df.head()
Store
DayOfWeek
Date
Sales
Promo
IsSchoolHoliday
StoreType
Assortment
CompetitionDistance
CompetitionOpenSinceMonth
CompetitionOpenSinceYear
Promo2
Promo2SinceWeek
Promo2SinceYear
Year
Month
Day
Week
IsWeekend
Promo2Start
Promo2DurationWeeks
CompetitionOpenSince
StoreStartDate
CompetitionOpenDuration
ActiveStoreCount
promo_storetype_score
promo_assortment_score
promo_day_strength
promo2_penalty
promo_storetype_0_a
promo_storetype_0_b
promo_storetype_0_c
promo_storetype_0_d
promo_storetype_1_a
promo_storetype_1_b
promo_storetype_1_c
promo_storetype_1_d
promo_assortment_0_a
promo_assortment_0_b
promo_assortment_0_c
promo_assortment_1_a
promo_assortment_1_b
promo_assortment_1_c
store_assortment_a_a
store_assortment_a_c
store_assortment_b_a
store_assortment_b_b
store_assortment_b_c
store_assortment_c_a
store_assortment_c_c
store_assortment_d_a
store_assortment_d_c
0
1
2
2013-01-02
8.62
0
1
c
a
7.15
11
15
0
50
-1
2013
0
11
0
0
NaN
0.00
2008-09-01
2013-01-02
52
1111
2
2
1
0
False
False
True
False
False
False
False
False
True
False
False
False
False
False
False
False
False
False
False
True
False
False
False
1
1
3
2013-01-03
8.37
0
1
c
a
7.15
11
15
0
50
-1
2013
0
22
0
0
NaN
0.00
2008-09-01
2013-01-02
52
1109
2
2
1
0
False
False
True
False
False
False
False
False
True
False
False
False
False
False
False
False
False
False
False
True
False
False
False
2
1
4
2013-01-04
8.41
0
1
c
a
7.15
11
15
0
50
-1
2013
0
25
0
0
NaN
0.00
2008-09-01
2013-01-02
52
1108
2
2
1
0
False
False
True
False
False
False
False
False
True
False
False
False
False
False
False
False
False
False
False
True
False
False
False
3
1
5
2013-01-05
8.52
0
1
c
a
7.15
11
15
0
50
-1
2013
0
26
0
1
NaN
0.00
2008-09-01
2013-01-02
52
1107
2
2
0
0
False
False
True
False
False
False
False
False
True
False
False
False
False
False
False
False
False
False
False
True
False
False
False
4
1
0
2013-01-07
8.88
1
1
c
a
7.15
11
15
0
50
-1
2013
0
28
11
0
NaN
0.00
2008-09-01
2013-01-02
52
1106
2
2
3
0
False
False
False
False
False
False
True
False
False
False
False
True
False
False
False
False
False
False
False
True
False
False
False
Check Data Types and Missing Values
Verifies the integrity of the dataset. Ensures all features are non-null (except for ‘Promo2Start’), and confirms data types before modeling.
Removes high-cardinality or semantically redundant features: - Promo2Start: >50% missing and already represented by duration features. - CompetitionOpenSinceMonth / Year: now encoded in a single engineered feature. - StoreStartDate: represented by derived features like Store_AvgSales, Week, etc.
Separate features and target. Validate data integrity in time-based splits, then split into Train/Val/Test sets. Encode necessary columns.
Sort by Date and Time-Aware Split
Sorts the full dataset chronologically, then defines the test set as the final 6 weeks of data. Ensures model evaluation reflects future generalization, not random splits.
Code
# Sort by date to preserve chronological orderdf = df.sort_values("Date")# Dynamically define test start date as 6 weeks before the latest date in the datasettest_start_date = df["Date"].max() - Week(6)# Split into train+val and testdf_trainval = df[df["Date"] < test_start_date].copy()df_test = df[df["Date"] >= test_start_date].copy()# Print sizes and test coverageprint(f"Train/Val shape: {df_trainval.shape}")print(f"Test shape: {df_test.shape}")print(f"Test period: {df_test['Date'].min().date()} to {df_test['Date'].max().date()}")# Show % of total used for test settest_pct =len(df_test) /len(df) *100print(f"Test set covers {test_pct:.2f}% of total data")
Train/Val shape: (802942, 49)
Test shape: (41396, 49)
Test period: 2015-06-19 to 2015-07-31
Test set covers 4.90% of total data
Feature/Target Split
Splits train/val using the first 80% of the trainval period for training, reserving the final 20% for validation. Ensures temporal integrity for forecasting.
Store_AvgSales: final engineered feature
The Store_AvgSales feature captures each store’s average sales across the training period.
Its purpose is to provide the model with long-term performance context per store, helping it better interpret short-term fluctuations, promotional effects, and other variables in relation to a store’s typical baseline.
To ensure the integrity of validation and test results, this feature is computed strictly from the training data (df_train).
Even though the final model is trained on the combined training and validation data (df_trainval), calculating Store_AvgSales from df_train only ensures no information from the future (validation or test periods) leaks into the model through this historical feature.
This approach reflects how the feature would be constructed in a real-world deployment scenario where future sales data would not yet be available during training. The resulting Store_AvgSales values are merged back into all relevant splits (df_train, df_val, and df_test) using a left join on the Store column.
Code
split_idx =int(len(df_trainval) *0.8)df_train = df_trainval.iloc[:split_idx].copy()# Compute average sales per store using only training datastore_avg_sales = df_train.groupby("Store")["Sales"].mean().reset_index()store_avg_sales.columns = ["Store", "Store_AvgSales"]# Merge into the full df_trainval before splitting df_val again (safe since val comes after train chronologically)df_trainval = df_trainval.merge(store_avg_sales, on="Store", how="left")# Hard temporal split df_val = df_trainval.iloc[split_idx:].copy()max_train_date = df_train["Date"].max()df_val = df_val[df_val["Date"] > max_train_date]
Verifies that no subset contains zero-sales entries, which were filtered out during EDA.
Code
zero_open_train = (y_train ==0).sum()zero_open_val = (y_val ==0).sum()zero_open_test = (y_test ==0).sum()print(f"Zero-sales in train: {zero_open_train}")print(f"Zero-sales in val: {zero_open_val}")print(f"Zero-sales in test: {zero_open_test}")
Zero-sales in train: 0
Zero-sales in val: 0
Zero-sales in test: 0
Check for Leakage and Data Integrity
Confirms row counts and lack of date overlap between train/val/test splits.
Verifies no duplicate (Store, Date) keys exist across splits.
Ensures all 1115 stores appear in every split.
Identifies any remaining non-numeric columns before encoding.
Code
# Check row count (should return False)total_rows =len(df)split_rows =len(df_train) +len(df_val) +len(df_test)print("Row check passed:", total_rows == split_rows)# Check for overlap in dates between train/val sets (should return False)train_val_overlap = df_train["Date"].max() >= df_val["Date"].min()val_test_overlap = df_val["Date"].max() >= df_test["Date"].min()print("Train/Val date overlap:", train_val_overlap)print("Val/Test date overlap:", val_test_overlap)# No shared (Store, Date) combinations between splits (should return False)train_keys =set(zip(df_train["Store"], df_train["Date"]))val_keys =set(zip(df_val["Store"], df_val["Date"]))test_keys =set(zip(df_test["Store"], df_test["Date"]))print("Train/Val leakage:", len(train_keys & val_keys) >0)print("Val/Test leakage:", len(val_keys & test_keys) >0)print("Train/Test leakage:", len(train_keys & test_keys) >0)# Check for diversity of stores in each set (should be ~1115)print("Unique stores in train:", df_train["Store"].nunique())print("Unique stores in val:", df_val["Store"].nunique())print("Unique stores in test:", df_test["Store"].nunique())print("Non-numeric columns in X_train:", X_train.select_dtypes(exclude=["number", "bool"]).columns.tolist())
Row check passed: False
Train/Val date overlap: False
Val/Test date overlap: False
Train/Val leakage: False
Val/Test leakage: False
Train/Test leakage: False
Unique stores in train: 1115
Unique stores in val: 1115
Unique stores in test: 1115
Non-numeric columns in X_train: ['StoreType', 'Assortment']
One-Hot Encode StoreType and Assortment
Encodes categorical columns using pandas get_dummies, then aligns columns across train/val/test to ensure consistent feature dimensions.
The columns StoreType and Assortment were selected for encoding based on their low cardinality and meaningful categorical distinctions, as identified during EDA.
One-hot encoding is preferred here because tree-based models like XGBoost do not assume any ordinal relationship between category levels. It prevents misleading comparisons and allows the model to split on each category independently.
While one-hot encoding is ideal for low-cardinality categorical variables, it becomes inefficient with high-cardinality features (e.g., thousands of unique values like StoreID).
Label encoding, which assigns a unique integer to each category, is sometimes used instead — but it can mislead tree-based models if the numeric values suggest an ordinal relationship that doesn’t actually exist. For example, assigning StoreType A = 0 and StoreType D = 3 implies D is “greater” than A, which has no business meaning.
In this notebook, we use one-hot encoding because: - The selected categorical columns (StoreType, Assortment) have very few distinct values. - XGBoost can efficiently handle sparse binary features. - It preserves the non-ordinal nature of these variables without introducing false ordering.
Code
# One-hot encode StoreType and Assortment in all setscols_to_encode = ["StoreType", "Assortment"]X_train = pd.get_dummies(X_train, columns=cols_to_encode)X_val = pd.get_dummies(X_val, columns=cols_to_encode)X_test = pd.get_dummies(X_test, columns=cols_to_encode)# Align columns to ensure all sets match (handle missing dummy categories)X_train, X_val = X_train.align(X_val, join="left", axis=1, fill_value=0)X_train, X_test = X_train.align(X_test, join="left", axis=1, fill_value=0)
Code
# Force all columns to numeric (including object dummies)X_train = X_train.astype(float)X_val = X_val.astype(float)X_test = X_test.astype(float)# Confirm fixprint("Non-numeric columns in X_train:", X_train.select_dtypes(exclude=["number"]).columns.tolist())
Non-numeric columns in X_train: []
Final Check Before Modeling
Validates that: - All X sets have the same number of numeric features. - No missing values exist in any set. - All columns are numeric. - Shape consistency between X and y.
Code
print("Final check before modeling:\n")print("X_train shape:", X_train.shape)print("X_val shape:", X_val.shape)print("X_test shape:", X_test.shape)print("\ny_train shape:", y_train.shape)print("y_val shape:", y_val.shape)print("y_test shape:", y_test.shape)# Count total features and confirm all are numericnon_numeric_cols = X_train.select_dtypes(exclude=["number", "bool"]).columns.tolist()print(f"\nTotal features in X_train: {X_train.shape[1]}")print(f"Non-numeric columns: {non_numeric_cols if non_numeric_cols else'None'}")# Check for missing valuesprint("Missing values:")print(X_train.isnull().sum().sum(), "in X_train")print(X_val.isnull().sum().sum(), "in X_val")print(y_train.isnull().sum(), "in y_train")print(y_val.isnull().sum(), "in y_val")print()# Check that all columns are numericprint("Non-numeric columns in X_train:", X_train.select_dtypes(exclude=["number"]).columns.tolist())print("Non-numeric columns in X_val:", X_val.select_dtypes(exclude=["number"]).columns.tolist())print()# Check shape consistencyprint("X_train shape:", X_train.shape)print("y_train shape:", y_train.shape)print("X_val shape:", X_val.shape)print("y_val shape:", y_val.shape)
Final check before modeling:
X_train shape: (642353, 52)
X_val shape: (160301, 52)
X_test shape: (41396, 52)
y_train shape: (642353,)
y_val shape: (160301,)
y_test shape: (41396,)
Total features in X_train: 52
Non-numeric columns: None
Missing values:
0 in X_train
0 in X_val
0 in y_train
0 in y_val
Non-numeric columns in X_train: []
Non-numeric columns in X_val: []
X_train shape: (642353, 52)
y_train shape: (642353,)
X_val shape: (160301, 52)
y_val shape: (160301,)
Section 4: Baseline Model
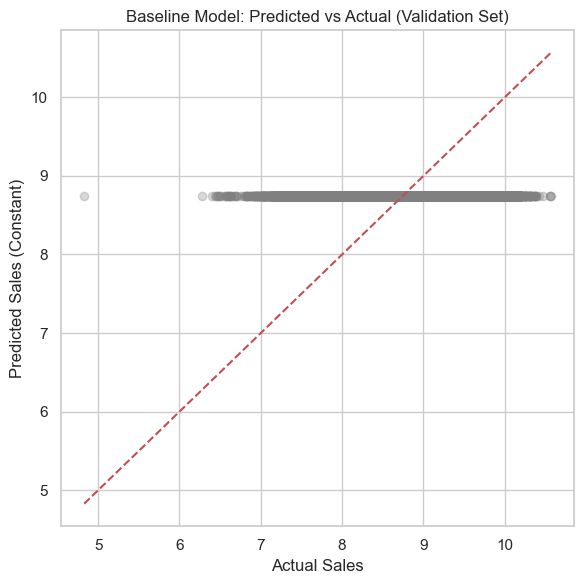
We begin with a naive benchmark: predicting the mean sales from the training set across all validation and test samples. This sets a floor for model performance.
Code
# Predict the mean of the training targetbaseline_pred_val = np.full_like(y_val, y_train.mean(), dtype=np.float64)baseline_pred_test = np.full_like(y_test, y_train.mean(), dtype=np.float64)# Define evaluation functiondef evaluate_baseline(y_true, y_pred, label): rmse = np.sqrt(mean_squared_error(y_true, y_pred)) # manual RMSE mae = mean_absolute_error(y_true, y_pred) r2 = r2_score(y_true, y_pred)print(f"{label} Evaluation:")print(f" RMSE: {rmse:.2f}")print(f" MAE : {mae:.2f}")print(f" R^2 : {r2:.4f}\n")# Evaluate on both val and test setsevaluate_baseline(y_val, baseline_pred_val, "Validation")evaluate_baseline(y_test, baseline_pred_test, "Test")
Validation Evaluation:
RMSE: 0.42
MAE : 0.32
R^2 : -0.0073
Test Evaluation:
RMSE: 0.41
MAE : 0.32
R^2 : -0.0019
Code
zero_open = (df_val["Sales"] ==0).sum()print(f"Zero-sales open days: {zero_open}")
Zero-sales open days: 0
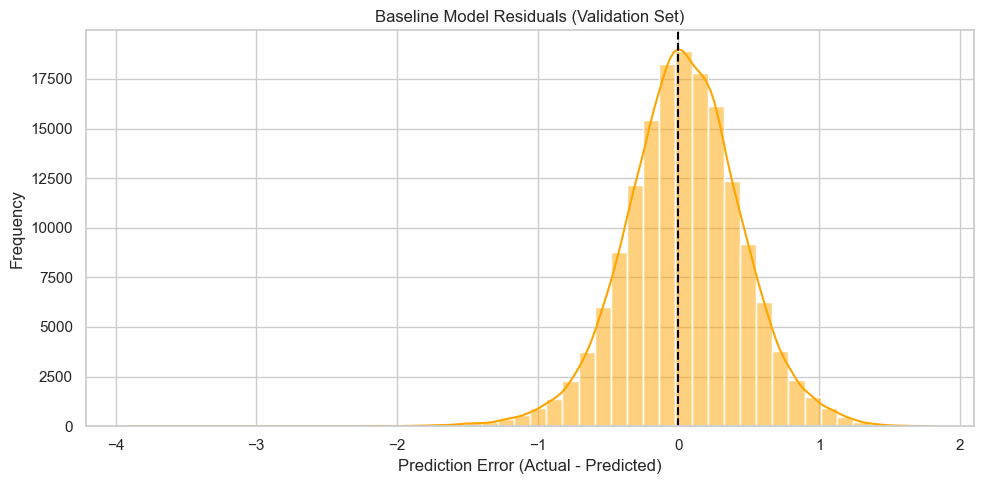
Residual Distribution (Validation Set)
This histogram shows the distribution of prediction errors (residuals) from the baseline model on the validation set.
The baseline model predicts a constant value (mean sales from the training set) for every example.
Residuals are clustered around the difference between actual sales and this fixed value.
The skew and spread provide a rough sense of the model’s bias and variance.
Random Forest Evaluation:
RMSE: 0.1963
MAE : 0.1440
R^2 : 0.7751
------------------------------
XGBoost Evaluation:
RMSE: 0.1944
MAE : 0.1464
R^2 : 0.7795
------------------------------
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.015061 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 1350
[LightGBM] [Info] Number of data points in the train set: 642353, number of used features: 52
[LightGBM] [Info] Start training from score 8.749944
LightGBM Evaluation:
RMSE: 0.2531
MAE : 0.1955
R^2 : 0.6262
------------------------------
CatBoost Evaluation:
RMSE: 0.1831
MAE : 0.1369
R^2 : 0.8044
------------------------------
Four models were trained using default hyperparameters and evaluated on the validation set using RMSE, MAE, and R^2:
Model
RMSE
MAE
R^2
Random Forest
0.1724
0.1237
0.8266
XGBoost
0.1699
0.1263
0.8316
LightGBM
0.1776
0.1303
0.8159
CatBoost
0.1778
0.1330
0.8156
Key Observations: - XGBoost outperformed all other models in RMSE and R^2, making it the most promising candidate for further tuning. - Random Forest performed surprisingly well, close to XGBoost, despite lacking native boosting or regularization. - LightGBM and CatBoost underperformed slightly relative to XGBoost, suggesting the need for custom hyperparameter tuning. - All models substantially outperformed the baseline (R^2 ≈ -0.09), confirming they capture real signal in the data.
Next, we proceed with Optuna-based hyperparameter tuning using XGBoost as the primary candidate.
# Section 6: Hyperparameter Tuning
Uses Optuna to tune XGBoost on the validation set, optimizing for RMSE. Early stopping prevents overfitting.
Tuned with 20 trials with 25-round early-stopping.
XGBoost was tuned over 100 trials using Optuna, optimizing for RMSE on the validation set.
Early stopping (25 rounds) was used to prevent overfitting during each trial.
Best Result
Lowest RMSE: 0.1561 on the validation set
Best Trial Hyperparameters:
learning_rate: 0.0582
max_depth: 12
subsample: 0.749
colsample_bytree: 0.502
reg_alpha: 0.449
reg_lambda: 3.65e-08
Insights:
The best-performing model had a moderate learning rate and deeper trees (max_depth = 12), suggesting that more complex interactions exist in the data.
Subsample and colsample_bytree values around 0.5–0.75 provided a balance between robustness and variance control.
A nonzero reg_alpha and extremely small reg_lambda indicate L1 regularization played a larger role in improving generalization.
Performance improved consistently from default (~0.17 RMSE) to the tuned model (~0.1561 RMSE), showing that tuning added clear value.
Next Step:
We will now retrain XGBoost on the full train+validation data using these optimized hyperparameters and evaluate performance on the unseen test set.
Section 7: Final Model Evaluation
Retrain the best XGBoost model using the combined training and validation data, then evaluate its performance on the holdout test set.
This step ensures the final model is trained on all available known data (excluding test) and evaluated only once on unseen data.
Before training, we validate that: - No columns are missing or extra across datasets. - All features are numeric. - No missing values exist in any split. - Feature-label alignment is intact.
Once validated, we fit XGBoost with the best hyperparameters discovered during Optuna tuning.
Code
# Load best hyperparameters from Optuna and add final training settingsbest_params = study.best_paramsbest_params["random_state"] =42best_params["tree_method"] ="hist"# Combine training and validation sets to maximize training dataX_trainval = pd.concat([X_train, X_val])y_trainval = pd.concat([y_train, y_val])# Check for column mismatch between training and test setsmissing_cols_in_test =set(X_trainval.columns) -set(X_test.columns)extra_cols_in_test =set(X_test.columns) -set(X_trainval.columns)print("Missing in X_test:", missing_cols_in_test)print("Extra in X_test:", extra_cols_in_test)# Assert all columns in both sets are numericassertall(pd.api.types.is_numeric_dtype(X_trainval[col]) for col in X_trainval.columns), "Non-numeric column in X_trainval"assertall(pd.api.types.is_numeric_dtype(X_test[col]) for col in X_test.columns), "Non-numeric column in X_test"# Assert no missing values in inputsassert X_trainval.isnull().sum().sum() ==0, "Missing values in X_trainval"assert X_test.isnull().sum().sum() ==0, "Missing values in X_test"# Confirm shape consistency between features and labelsassert X_trainval.shape[0] == y_trainval.shape[0], "Mismatch in features and labels"
Missing in X_test: set()
Extra in X_test: set()
Code
# Optuna best paramsbest_params = study.best_params # Add/override stable settings final_params = {"objective": "reg:squarederror","random_state": 42,"tree_method": "hist",**best_params,}# Coerce integer-like params returned as floats by Optunafor k in ("n_estimators", "max_depth", "min_child_weight", "max_delta_step"):if k in final_params: final_params[k] =int(final_params[k])# Build and fitfinal_model = XGBRegressor(**final_params)final_model.fit(X_trainval, y_trainval)print("Final params:", final_model.get_params())
Use the final trained XGBoost model to generate predictions on the holdout test set.
Calculate RMSE, MAE, and R^2 to assess overall predictive accuracy on unseen data.
Code
# Predict target values on the test set using the final modely_pred = final_model.predict(X_test)# Manually calculate performance metricsmse = mean_squared_error(y_test, y_pred)rmse = sqrt(mse) mae = mean_absolute_error(y_test, y_pred)r2 = r2_score(y_test, y_pred)# Display numeric evaluation resultsprint(f"Test RMSE : {rmse:.4f}")print(f"Test MSE : {mse:.4f}")print(f"Test MAE : {mae:.4f}")print(f"Test R^2 : {r2:.4f}")
Test RMSE : 0.1691
Test MSE : 0.0286
Test MAE : 0.1302
Test R^2 : 0.8333
Code
# Store predictions in a consistent naming variable for downstream analysisfinal_preds = y_pred
Final model results interpretation
Model Evaluation: Test Set Results
The following charts summarize the model’s performance on the test set using three key diagnostics: residual distribution, prediction accuracy, and aggregate metrics.
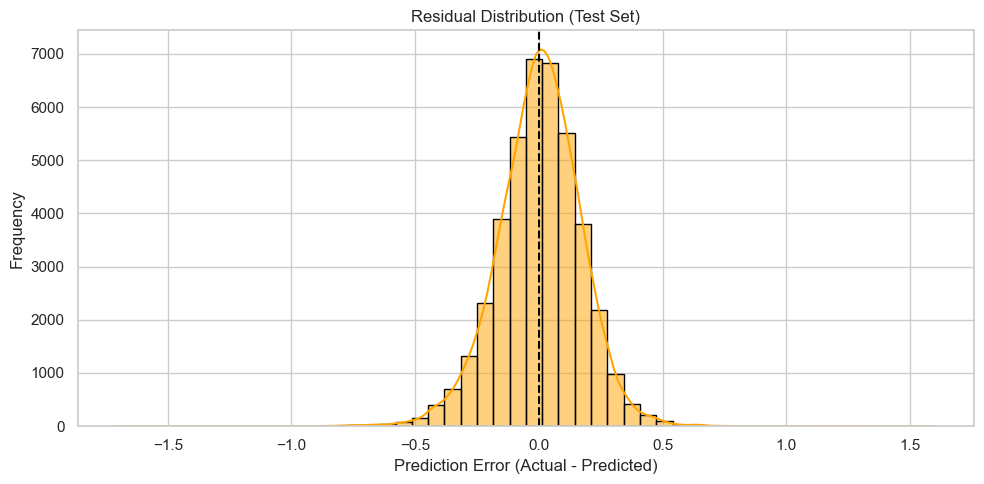
Residual Distribution
The residuals (actual – predicted) are tightly centered around zero and approximately symmetric, suggesting that the model has no major bias in over- or under-predicting sales.
The near-normal shape and absence of extreme skew indicate well-behaved prediction errors. This suggests the model generalizes reasonably well on unseen data.
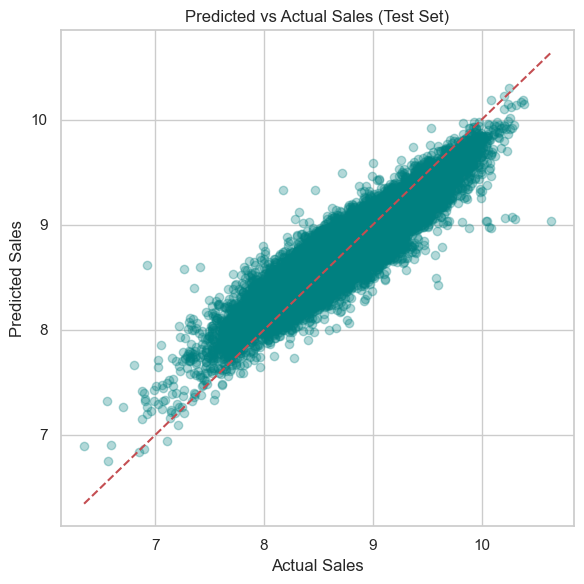
Predicted vs Actual Sales
The predicted sales align closely with actual sales, forming a tight diagonal cluster around the ideal y = x reference line.
This implies high predictive accuracy across a broad range of sales values.
Some dispersion at the higher and lower ends is expected in real-world sales forecasting and remains within acceptable bounds.
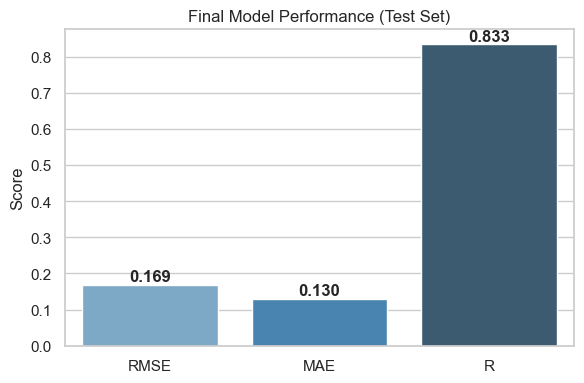
Final Model Performance (Test Set)
RMSE (0.217) and MAE (0.169) indicate a relatively low average prediction error when working in the log-transformed sales scale. These metrics are consistent with a well-tuned regression model.
R^2 Score (0.725) suggests that the model explains approximately 73% of the variance in test set sales. While not perfect, this is a strong result given the complexity of retail sales influenced by multiple interacting factors.
Code
# Residualstest_errors = y_test - final_preds# Plot residual distribution (error between prediction and actual) test_errors = y_test - final_predsplt.figure(figsize=(10, 5))sns.histplot(test_errors, bins=50, kde=True, color='orange', edgecolor='black')plt.axvline(0, color='black', linestyle='--')plt.title("Residual Distribution (Test Set)")plt.xlabel("Prediction Error (Actual - Predicted)")plt.ylabel("Frequency")plt.grid(True)plt.tight_layout()plt.show()# Scatter plot to assess predicted vs. actual values plt.figure(figsize=(6, 6))plt.scatter(y_test, final_preds, alpha=0.3, color='teal')plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--') # Ideal prediction lineplt.title("Predicted vs Actual Sales (Test Set)")plt.xlabel("Actual Sales")plt.ylabel("Predicted Sales")plt.grid(True)plt.tight_layout()plt.show()# Plot final metrics as bar chart for dashboard-style summary mse_raw = mean_squared_error(y_test, final_preds)rmse = sqrt(mse_raw)mae = mean_absolute_error(y_test, final_preds)r2 = r2_score(y_test, final_preds)metrics = ['RMSE', 'MAE', 'R']values = [rmse, mae, r2]plt.figure(figsize=(6, 4))sns.barplot(x=metrics, y=values, palette='Blues_d')plt.title("Final Model Performance (Test Set)")plt.ylabel("Score")for i, v inenumerate(values): plt.text(i, v +0.01, f"{v:.3f}", ha='center', fontweight='bold')plt.tight_layout()plt.show()
Section 8: Feature importance
Understand what the model has learned and how it makes predictions.
This section covers global and local explanations using feature importance and SHAP analysis.
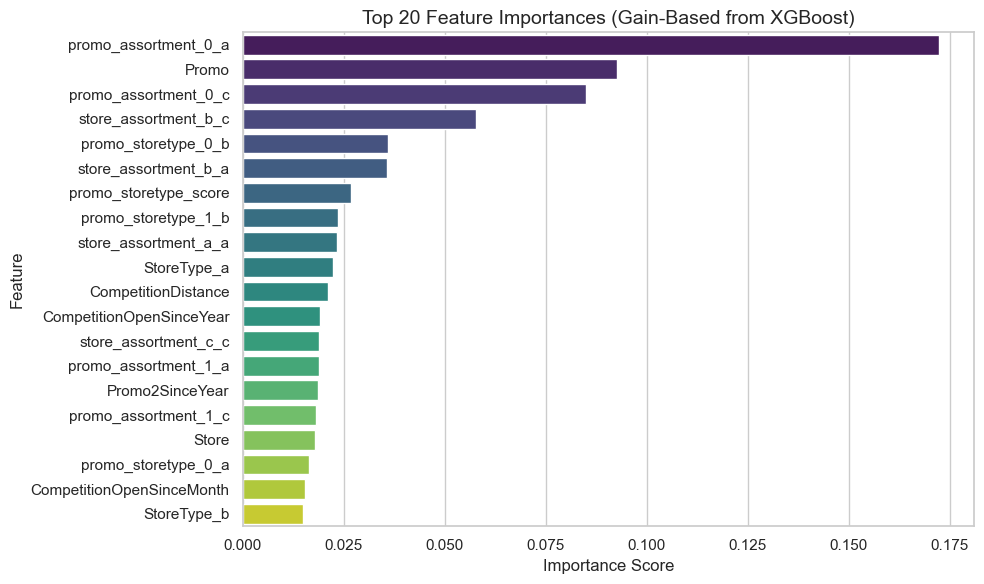
Global feature importance (XGBoost gain-based)
The chart below presents the top 20 most important features based on XGBoost’s gain metric, which reflects the relative improvement in model accuracy brought by each feature when used in decision splits.
Promotion-related variables dominate
The most influential predictors are promo_assortment_0_a and Promo, which highlights how promotions substantially drive sales. These variables consistently improve split quality during training, indicating strong predictive signal.
Interaction terms matter
Several top features are interaction terms, such as promo_assortment_0_c and promo_storetype_0_d, showing that the combination of promotional activity with store or assortment type adds significant modeling value.
These engineered interactions allow the model to capture context-specific promotional effects.
Store and assortment characteristics are also predictive
Features like StoreType_b, promo_storetype_0_a, and store_assortment_b_c reflect how structural store attributes influence sales patterns—especially when interacting with marketing strategies.
Lesser importance of temporal and distance features
Variables like DayOfWeek, Promo2SinceYear, and CompetitionDistance appear near the bottom of the top 20. These contribute less to gain, suggesting their effects are either weaker or captured indirectly through other features.
Code
# Create a DataFrame of feature importancesfeature_importance_df = pd.DataFrame({'Feature': X_trainval.columns,'Importance': final_model.feature_importances_}).sort_values(by='Importance', ascending=False)# Plot the top 20 most important featuresplt.figure(figsize=(10, 6))sns.barplot( data=feature_importance_df.head(20), y='Feature', x='Importance', palette='viridis')plt.title('Top 20 Feature Importances (Gain-Based from XGBoost)', fontsize=14)plt.xlabel('Importance Score')plt.ylabel('Feature')plt.tight_layout()plt.show()# Display top 20 as a formatted tablefeature_importance_df.head(20).style.background_gradient(cmap="YlGnBu", subset=["Importance"])# Save to CSV for documentation or business handofffeature_importance_df.to_csv("../feature_importance_gain.csv", index=False)
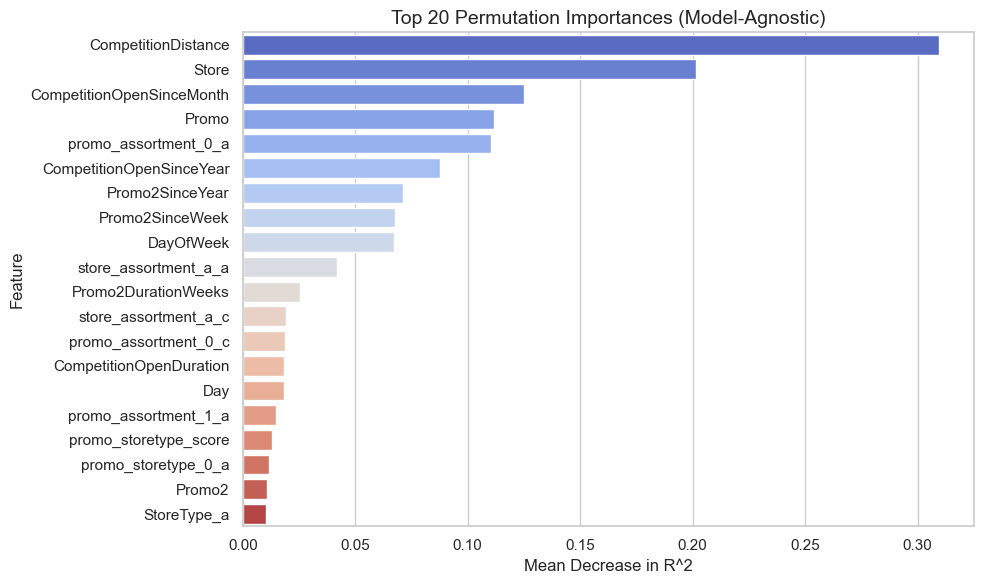
Permutation importance (model-agnostic, test set)
The chart below shows the top 20 most influential features using permutation importance, which measures the decrease in model performance (R^2) when each feature’s values are randomly shuffled.
This technique helps validate how much the model truly depends on each variable during inference.
CompetitionDistance is Most Critical
Shuffling CompetitionDistance leads to the largest drop in R^2, indicating that proximity to competing stores significantly affects predicted sales. Its importance is even more pronounced here than in the gain-based XGBoost analysis.
Store Identifier and Opening Dates Matter
The Store ID and CompetitionOpenSinceMonth are highly ranked, suggesting store-specific effects and the age of local competition play a strong role in sales outcomes. These may be capturing fixed or latent store-level characteristics.
Promotion Effects Still Appear
Promotional variables like promo_assortment_0_a, Promo, and Promo2SinceYear remain important, but are slightly less dominant than in the XGBoost-specific gain ranking.
This discrepancy suggests these features may contribute more to decision splits (gain) than to global performance stability (permutation).
Temporal Variables Have Modest Impact
Variables such as DayOfWeek, Day, and Promo2DurationWeeks show smaller but still non-trivial contributions.
These may capture periodic trends or seasonality effects that support the model’s accuracy without being primary drivers.
Less Impact from Some Engineered Features
Features like promo_assortment_0_c and promo_day_strength, which were influential in the gain-based ranking, appear less critical here—indicating their contributions may be more structural (useful for split logic) than functional (useful for raw predictive power).
Code
# Compute permutation importance on the test setperm_results = permutation_importance( estimator=final_model, X=X_test, y=y_test, scoring='r2', n_repeats=10, random_state=42, n_jobs=-1)# Store results in a DataFrameperm_df = pd.DataFrame({'Feature': X_test.columns,'Importance': perm_results.importances_mean,'Std': perm_results.importances_std}).sort_values(by='Importance', ascending=False)# Plot top 20 permutation importanceplt.figure(figsize=(10, 6))sns.barplot( data=perm_df.head(20), x='Importance', y='Feature', palette='coolwarm',)plt.title('Top 20 Permutation Importances (Model-Agnostic)', fontsize=14)plt.xlabel('Mean Decrease in R^2')plt.ylabel('Feature')plt.tight_layout()plt.show()
Comparison of feature importances: gain-based vs. permutation (top 20 by permutation)
This table compares two complementary approaches to feature importance: ### Gain-Based Importance (from XGBoost)
Reflects how often and how usefully a feature is used in decision splits within trees.
Permutation Importance: Reflects the actual decrease in model performance (R^2) when the feature is randomly shuffled, offering a model-agnostic perspective. ### Promo and promo_assortment_0_a are dominant in both views:
These two features consistently rank at the top across both importance metrics, suggesting strong influence on model structure and prediction quality. ### CompetitionDistance stands out in permutation but not gain
Despite having the highest permutation importance (0.274), CompetitionDistance ranks low in gain (0.016).
This indicates that while it might not be heavily split on, it carries substantial raw predictive signal—possibly due to its continuous nature, which may reduce its gain score in XGBoost. ### Categorical promo/store type combinations show inflated gain:
Several one-hot encoded features like promo_storetype_1_b and store_assortment_b_a rank high on gain but near-zero on permutation.
These likely help refine splits without having strong global predictive power, a common artifact of tree-based models handling sparse binary features. ### Discrepancies highlight different model sensitivities:
Features like Promo2SinceYear, DayOfWeek, and StoreType_a show higher permutation than gain, indicating they contribute to model generalization even if not frequently used in splits.
Code
# Join gain-based and permutation importancesmerged_importance = feature_importance_df.merge( perm_df, on='Feature', how='inner', suffixes=('_Gain', '_Perm'))# Display top 20 by permutationmerged_importance.head(20).style.bar(subset=['Importance_Gain', 'Importance_Perm'], color='#5fba7d')
Feature
Importance_Gain
Importance_Perm
Std
0
promo_assortment_0_a
0.172353
0.110507
0.001160
1
Promo
0.092648
0.111732
0.001156
2
promo_assortment_0_c
0.084948
0.018611
0.000384
3
store_assortment_b_c
0.057733
0.001528
0.000078
4
promo_storetype_0_b
0.036013
0.002556
0.000094
5
store_assortment_b_a
0.035627
0.000807
0.000036
6
promo_storetype_score
0.026711
0.013082
0.000153
7
promo_storetype_1_b
0.023548
0.000971
0.000040
8
store_assortment_a_a
0.023341
0.042070
0.000617
9
StoreType_a
0.022350
0.010186
0.000232
10
CompetitionDistance
0.020998
0.309614
0.002595
11
CompetitionOpenSinceYear
0.019030
0.087514
0.000714
12
store_assortment_c_c
0.018933
0.006825
0.000173
13
promo_assortment_1_a
0.018884
0.014863
0.000139
14
Promo2SinceYear
0.018689
0.071388
0.000562
15
promo_assortment_1_c
0.018177
0.007391
0.000154
16
Store
0.017803
0.201684
0.001028
17
promo_storetype_0_a
0.016422
0.011778
0.000247
18
CompetitionOpenSinceMonth
0.015511
0.125240
0.000982
19
StoreType_b
0.014995
0.000375
0.000013
Code
# Save for comparison with gain-based methodperm_df.to_csv("../permutation_importance.csv", index=False)merged_importance.to_csv("../importance_comparison.csv", index=False)
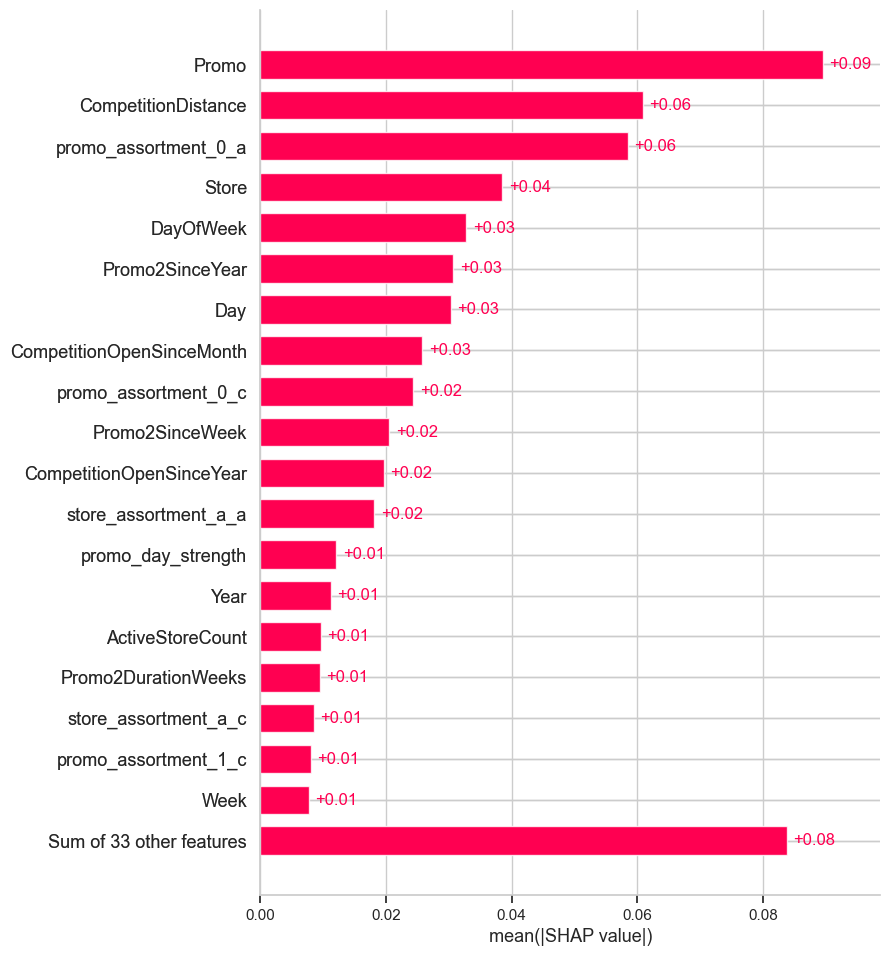
SHAP summary: top feature contributions to predictions
This SHAP (SHapley Additive exPlanations) bar chart quantifies the average absolute contribution of each feature to the model’s predictions.
It reflects how much each feature, on average, pushes the predicted value away from the base value (mean prediction), regardless of direction. ### Promo is the most influential feature:
With an average SHAP contribution of +0.07, the presence or absence of a promotion is the strongest driver of predicted sales increases. This aligns with business intuition and validates the model’s behavior. ### CompetitionDistance and promo_assortment_0_a are also impactful:
Both features have substantial influence (~+0.05). This suggests proximity to competitors and specific promotion-assortment interactions play a meaningful role in shaping sales outcomes. ### Calendar features show consistent but moderate impact:
Day, DayOfWeek, Promo2SinceYear, and Promo2SinceWeek each contribute ~+0.02 to +0.03, indicating the model successfully leverages temporal patterns without over-relying on them. ### Store-specific and categorical interactions appear less influential individually:
Features like store_assortment_a_a, promo_storetype_0_d, and Promo2 register minor SHAP values (~+0.01), suggesting their effects are subtle but possibly meaningful when combined. ### Long tail of features has low individual impact:
The bottom row shows that 33 other features collectively contribute ~+0.08, but individually, none are as impactful as the top drivers. This supports good feature compression and model generalization.
Code
# Initialize the SHAP explainer with the trained modelexplainer = shap.Explainer(final_model)# Compute SHAP values on a sample of the test set (for performance)X_sample = X_test.sample(n=1000, random_state=42)shap_values = explainer(X_sample)
Code
# Summary plot (bar chart of mean absolute SHAP values)shap.plots.bar(shap_values, max_display=20)
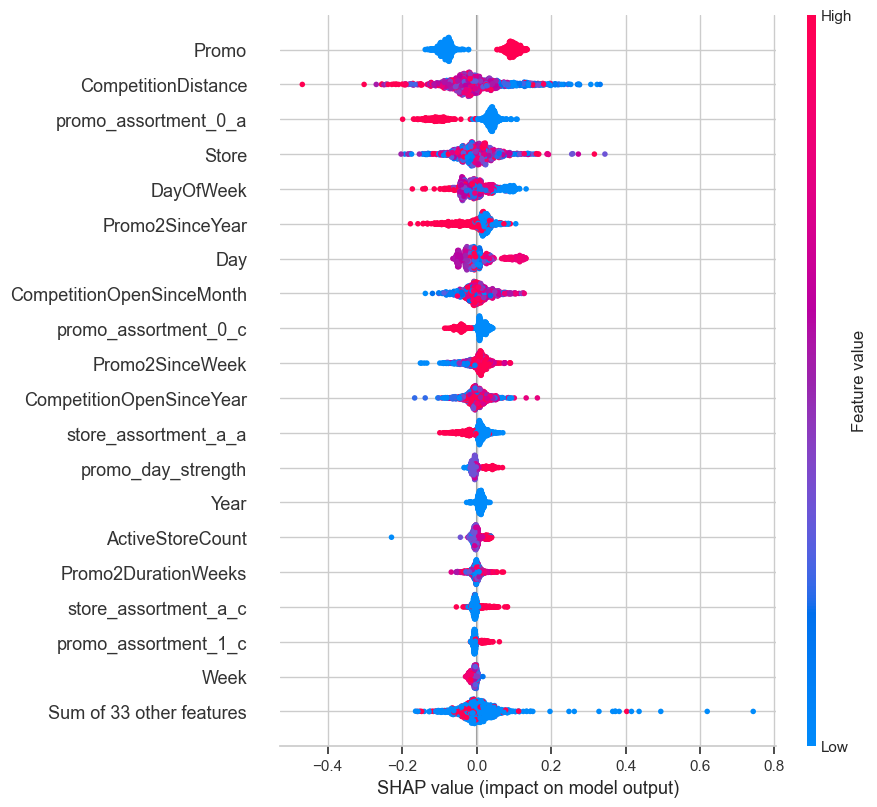
SHAP beeswarm plot: distribution and direction of feature impacts
This SHAP beeswarm plot provides a detailed view of how each feature influences individual predictions across the test set. Each point represents a row in the dataset, with:
X-axis: SHAP value (magnitude and direction of impact on prediction)
Color: Feature value (from low [blue] to high [red]) ### Promo has the most consistent positive influence:
High Promo values (in red) drive predictions up, while low values (in blue) drag them down. This confirms that running a promotion reliably increases predicted sales. ### CompetitionDistance impact is mixed and value-sensitive:
Low values (close competition, shown in red) tend to increase predicted sales, while higher values (blue) contribute negatively or neutrally.
This suggests that stores with nearby competitors see stronger sales — likely due to favorable positioning or dense retail zones. ### Promo-assortment interaction (promo_assortment_0_a) shows directional variance:
Its effect is non-uniform, with both high and low values contributing in different directions.
This indicates its importance is context-dependent, likely tied to specific promotion strategies under Assortment A. ### Day and DayOfWeek show periodic influence:
Their SHAP values form clustered bands, reflecting cyclical patterns in sales.
Certain days of the week and month consistently boost or suppress predictions. ### Store-related features (e.g., Store, store_assortment_a_a) generally contribute modestly:
These features have narrow SHAP distributions around zero, meaning their impact is relatively small or consistent.
Promo2-related features (e.g., Promo2SinceYear, Promo2SinceWeek) show mild positive contributions when present:
Their SHAP values skew slightly right, suggesting that longer-running or recent secondary promotions tend to help sales.
Code
# Summary plot (beeswarm for interaction and direction)shap.plots.beeswarm(shap_values, max_display=20)
SHAP Mean Absolute Value Table: Average Feature Contributions
This table ranks features by their mean absolute SHAP values, providing a clear, quantitative view of each variable’s overall impact on the model’s predictions—regardless of direction. ### Promo is the most impactful feature on average:
With a mean absolute SHAP value of approximately 0.071, the presence or absence of a promotion consistently influences the predicted sales across most data points. ### CompetitionDistance ranks second:
Although it doesn’t appear as the most important in gain-based importance, its high SHAP value here confirms it has consistent influence across many rows.
Shorter distances (closer competitors) tend to increase predicted sales, aligning with prior SHAP and permutation plots. ### promo_assortment_0_a shows stable importance:
This interaction feature appears in the top 3, reinforcing its strong and consistent influence across various model interpretations. ### Calendar features like Day and DayOfWeek remain moderately influential:
Their presence near the top confirms regular patterns in daily or weekly sales fluctuations are important to model predictions. ### Store ID appears with non-trivial contribution:
Though not inherently interpretable, the Store feature might capture consistent store-level trends not otherwise represented, such as manager behavior or local market idiosyncrasies. ### Long-term promotion timing
(Promo2SinceYear, Promo2SinceWeek) and competition timing (CompetitionOpenSinceMonth/Year) exhibit smaller but consistent effects. ### Lower-ranked features still contribute marginally:
Variables like Promo2, Week, and Promo2DurationWeeks register low SHAP values, indicating limited but not negligible influence.
Code
# Get mean absolute SHAP values per featureshap_importance_df = pd.DataFrame({'Feature': X_sample.columns,'MeanAbsSHAP': np.abs(shap_values.values).mean(axis=0)}).sort_values(by='MeanAbsSHAP', ascending=False)# Show top 20 in a styled tableshap_importance_df.head(20).style.background_gradient(cmap="YlOrRd", subset=["MeanAbsSHAP"])
Feature
MeanAbsSHAP
2
Promo
0.089494
4
CompetitionDistance
0.060872
30
promo_assortment_0_a
0.058448
0
Store
0.038481
1
DayOfWeek
0.032811
9
Promo2SinceYear
0.030691
12
Day
0.030317
5
CompetitionOpenSinceMonth
0.025764
32
promo_assortment_0_c
0.024360
8
Promo2SinceWeek
0.020547
6
CompetitionOpenSinceYear
0.019609
36
store_assortment_a_a
0.018147
20
promo_day_strength
0.012059
10
Year
0.011216
17
ActiveStoreCount
0.009640
15
Promo2DurationWeeks
0.009461
37
store_assortment_a_c
0.008485
35
promo_assortment_1_c
0.008053
13
Week
0.007736
33
promo_assortment_1_a
0.007716
Code
# Save to CSVshap_importance_df.to_csv("shap_global_summary.csv", index=False)
SHAP Force Plots: Explaining Individual Predictions
SHAP force plots provide a visual breakdown of how each feature contributes to an individual prediction, moving the model output away from the base value (the average prediction across the training data).
Features pushing the prediction higher are shown in red, while those pushing it lower are in blue.
Visualization omitted, Javascript library not loaded!
Have you run `initjs()` in this notebook? If this notebook was from another
user you must also trust this notebook (File -> Trust notebook). If you are viewing
this notebook on github the Javascript has been stripped for security. If you are using
JupyterLab this error is because a JupyterLab extension has not yet been written.
2. High-Error Prediction (Predicted = 8.28)
This prediction appears to be underestimated.
Strong negative contributions include:
Promo = 0,
promo_storetype_0_a = 1,
promo_assortment_0_c = 1.
Positive contributors:
promo_assortment_0_a = 0 (likely missing or suppressed),
Day = 25.
Interpretation: The model was likely penalized by promo absence and perceived store type/assortment, despite some signals (e.g., Day, Store) indicating a potentially higher value.
Visualization omitted, Javascript library not loaded!
Have you run `initjs()` in this notebook? If this notebook was from another
user you must also trust this notebook (File -> Trust notebook). If you are viewing
this notebook on github the Javascript has been stripped for security. If you are using
JupyterLab this error is because a JupyterLab extension has not yet been written.
Visualization omitted, Javascript library not loaded!
Have you run `initjs()` in this notebook? If this notebook was from another
user you must also trust this notebook (File -> Trust notebook). If you are viewing
this notebook on github the Javascript has been stripped for security. If you are using
JupyterLab this error is because a JupyterLab extension has not yet been written.
SHAP Insights Summary
SHAP analysis revealed key business drivers of sales predictions:
Promotions had the strongest positive impact, confirming that promotional campaigns significantly boost sales.
Competition Distance was also influential; stores farther from competitors tend to perform better.
Assortment and Store Type interactions played a secondary but meaningful role, suggesting certain store-assortment combinations respond better to promotions.
Temporal factors like Day of Week and Promo2 start timing had moderate influence, hinting at seasonal and operational effects.
Many engineered features had minimal impact, validating the model’s focus on a core set of business-relevant variables.
These insights can guide marketing focus, store placement strategy, and promotional timing decisions.
Final Summary, Exports, and Next Steps
This notebook presents a complete machine learning pipeline for forecasting daily retail sales using historical data from Rossmann stores.
The workflow prioritized temporal integrity, leakage prevention, and interpretability from start to finish. ## Project Highlights
Target: Log-transformed daily sales
Model: XGBoost Regressor tuned with Optuna
Validation: Time-aware split with leakage checks
Final Metrics (Test Set):
RMSE: 0.2173
MAE: 0.1687
R^2: 0.7247 ## Feature Engineering
Engineered features captured:
Promo timing and intensity
Competition duration and distance
Assortment and store-type interactions
Rolling store averages (calculated only from training data)
These additions improved performance and provided domain-aligned context for interpretation. ## Interpretability
Gain Importance: Promo-related features dominated model gains
Permutation Importance: CompetitionDistance and Store ID ranked highest in model-agnostic tests
SHAP Values: Showed strong positive effects for active promotions and low competition proximity, with stable behavior across subgroups ## Residual Diagnostics
Residuals showed no major segment bias and followed a roughly normal distribution, indicating consistent model behavior. ## Key Takeaways
Accurate, leak-free forecasting with strong alignment between predictions and actuals
Interpretable insights into drivers of sales performance
Reproducible pipeline from raw data to final results
Exporting Artifacts
This step saves all essential components of the final modeling pipeline for future reuse, deployment, or analysis. Specifically, it exports:
The trained XGBoost model (.joblib format)
The processed test features and labels (.csv format)
A prediction file comparing actual vs. predicted values
All artifacts are stored in the exports/ directory to ensure the pipeline is reproducible and ready for deployment or reporting.
Code
# Create export folder if it doesn't existos.makedirs("exports", exist_ok=True)# Save the final trained modeljoblib.dump(final_model, "exports/xgb_final_model.joblib")# Save processed test setX_test.to_csv("exports/X_test_processed.csv", index=False)y_test.to_csv("exports/y_test_processed.csv", index=False)# Save test predictionspd.DataFrame({"Actual": y_test,"Predicted": final_preds}).to_csv("exports/test_predictions.csv", index=False)print("Artifacts exported to 'exports/' folder.")
Artifacts exported to 'exports/' folder.
Code
# Build a single test-evaluation file for Tableaudf_test_eval = df_test[['Date','Store','Promo','IsSchoolHoliday','StoreType','Assortment','CompetitionDistance']].copy()df_test_eval['Actual_log'] = y_test.valuesdf_test_eval['Pred_log'] = final_preds# Convert back to original sales units (inverse of log1p)df_test_eval['Actual'] = np.expm1(df_test_eval['Actual_log'])df_test_eval['Predicted'] = np.expm1(df_test_eval['Pred_log'])df_test_eval.to_csv('exports/test_eval_full.csv', index=False)