Negative tweets emphasise disruption words “cancelled”, “service”, “hours”.
Positive tweets dominated by gratitude “thanks”, “love”, “great”.
Confirms that the cleaning pipeline retained sentiment‑bearing tokens and removed noise.
Code
# build separate corpora per sentimentcorpora = { sentiment: df.loc[df["airline_sentiment"] == sentiment, "clean_text"].tolist()for sentiment in ["negative", "neutral", "positive"]}# fit TF-IDF and grab top 10 terms for each vectorizer = TfidfVectorizer( stop_words="english", max_features=5_000, ngram_range=(1, 2),)top_terms = {}for sentiment, texts in corpora.items(): tfidf_matrix = vectorizer.fit_transform(texts)# average tf-idf per term & get top 10 indices avg_scores = tfidf_matrix.mean(axis=0).A1 top_idx = avg_scores.argsort()[::-1][:10] top_terms[sentiment] = [vectorizer.get_feature_names_out()[i] for i in top_idx]# show as a DataFrame top_df = pd.DataFrame(top_terms)display(top_df)# save to CSVtop_df.to_csv(FIG_DIR /"top_tfidf_terms.csv", index=False)
negative
neutral
positive
0
flight
flight
thanks
1
cancelled
thanks
thank
2
service
dm
flight
3
hours
fleek
great
4
customer
fleet
just
5
just
fleet fleek
love
6
hold
just
service
7
help
flights
best
8
time
help
good
9
plane
need
awesome
7. Key Insights
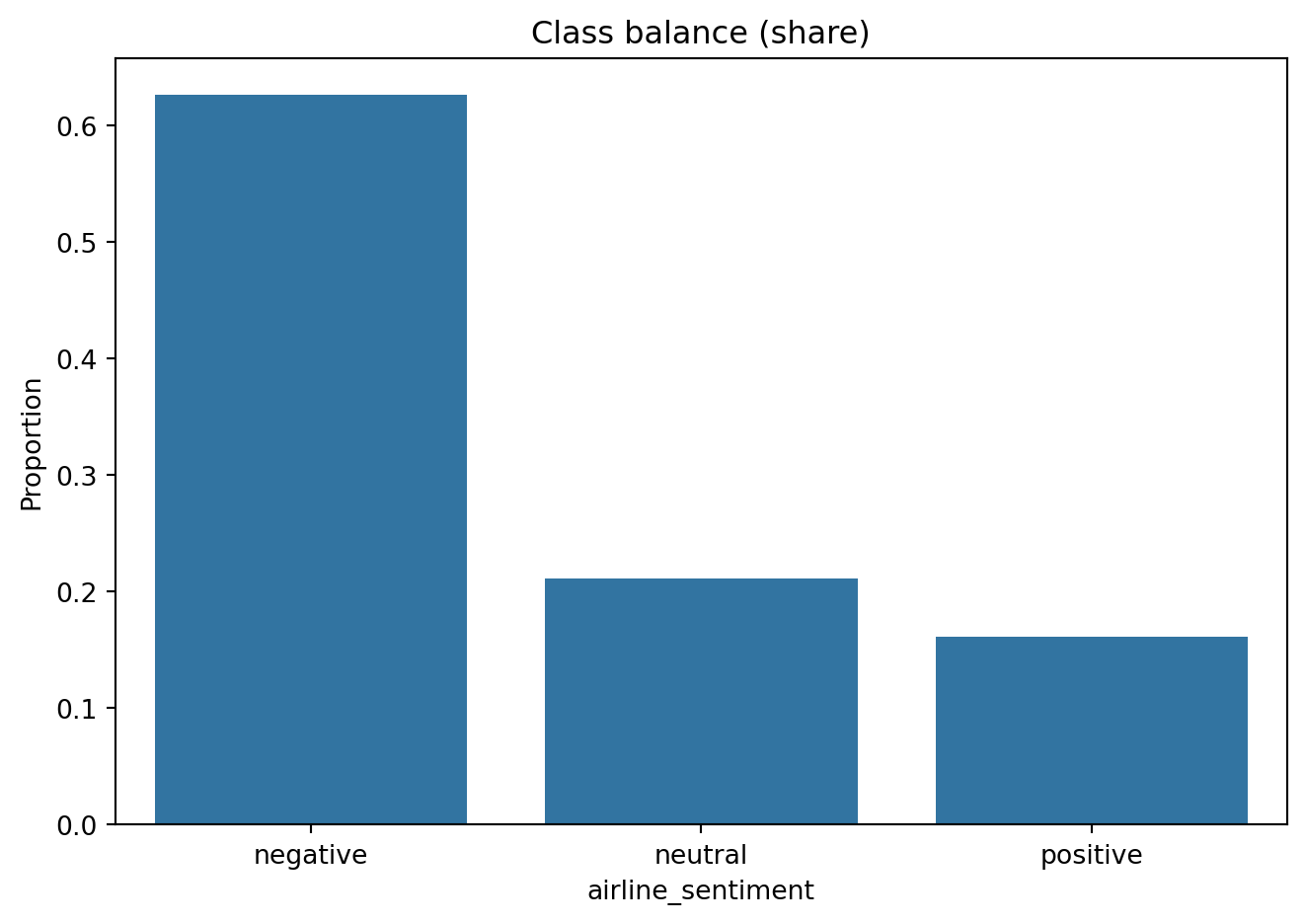
Label imbalance (63 % negative) demands stratified splits and weighting.
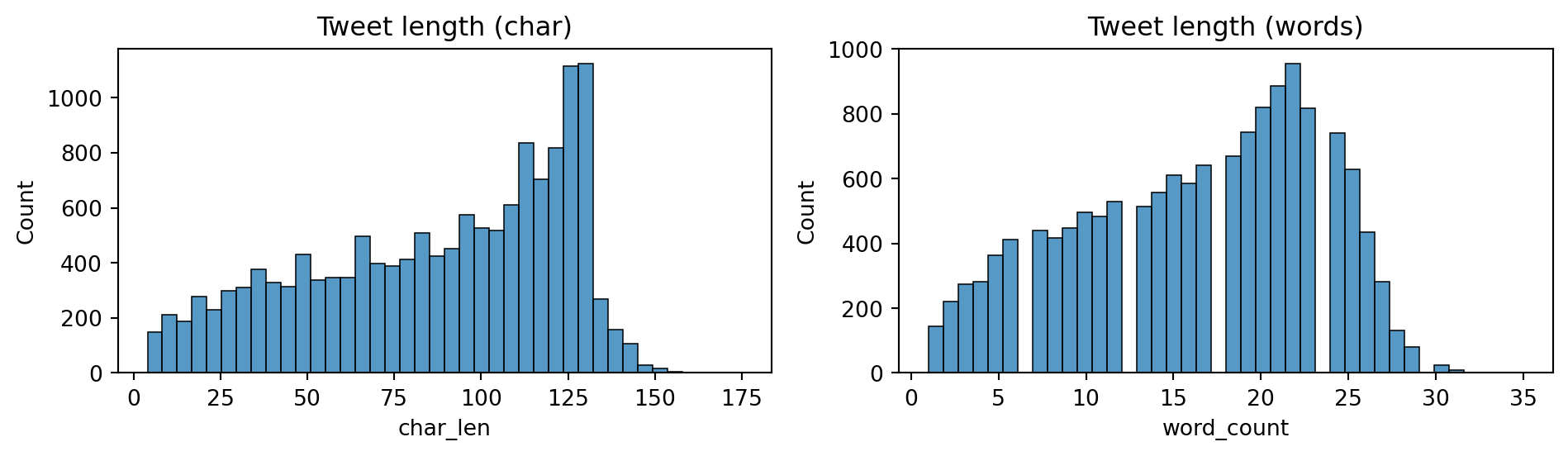
Typical tweet length ≈ 110 chars / 17 words → standard tokenizer window is sufficient.
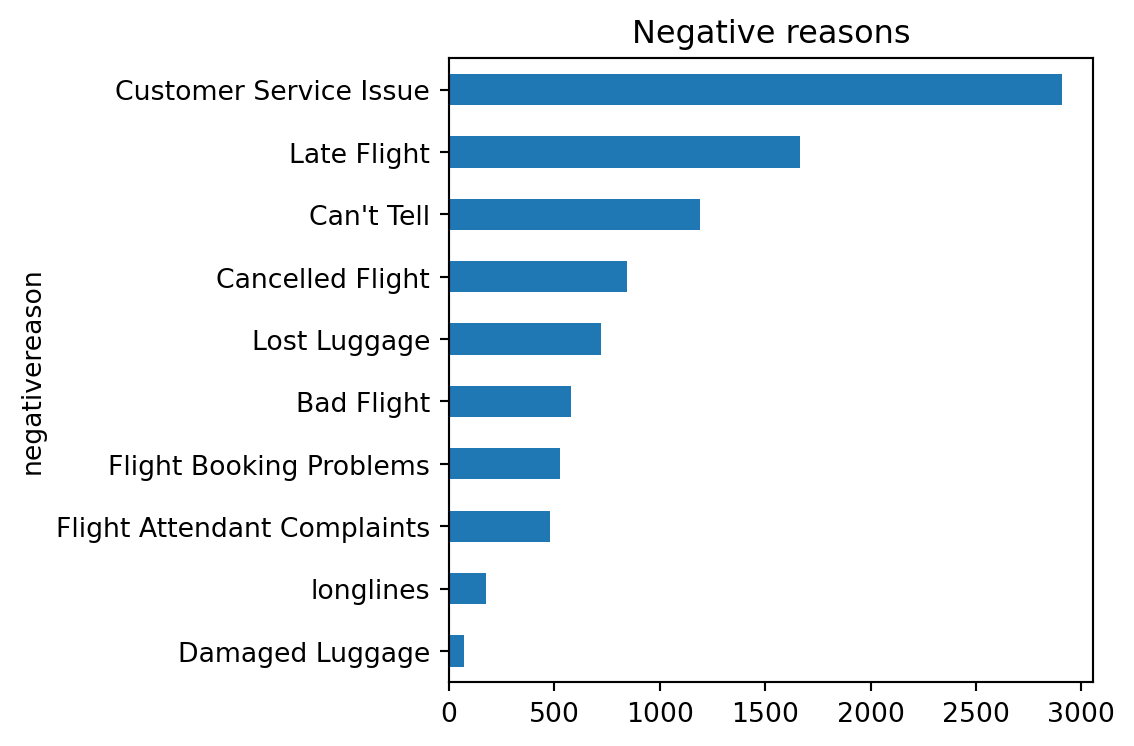
Customer‑service and late‑flight issues form > 50 % of negative reasons.
Virgin America and Southwest exhibit more positive sentiment → airline feature likely informative.
Next Steps
Finalise feature list — text (TF‑IDF / embeddings) + metadata (airline, time, etc.).
Select resampling or class‑weight strategy for modelling.
Prototype baseline models in 04_baseline_model.ipynb