Establish a reproducible TF‑IDF + Logistic Regression benchmark for Twitter‑airline sentiment.
Text column → clean_textTarget label → airline_sentiment (negative, neutral, positive)Train / validation / test = 70 / 15 / 15 (stratified)
Persist artefacts to models/
Notebook Outline
Load Processed Data & Train-Test Split Majority-class reference TF-IDF + Logistic Regression pipeline Validation performance 5-fold stratified CV on all data Persisted Artifacts Key Takeaway
Code
# Imports from __future__ import annotationsimport jsonfrom pathlib import Pathimport matplotlib.pyplot as pltimport joblibimport pandas as pdfrom sklearn.model_selection import (from sklearn.pipeline import Pipelinefrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import (# Detect project root (folder that contains "data/") = Path.cwd().parent # Define core directories = ROOT_DIR / "data" = DATA_DIR / "processed" = ROOT_DIR / "models" = ROOT_DIR / "reports" / "figs_04" = True )= True , exist_ok= True )# Locate tweets.parquet (processed > raw fallback) = (/ "tweets.parquet" if (PROC_DATA_DIR / "tweets.parquet" ).exists()else DATA_DIR / "tweets.parquet" assert PARQUET_PATH.exists(), f"Missing parquet at { PARQUET_PATH} " print (f"Project root : { ROOT_DIR} " )print (f"Parquet source : { PARQUET_PATH. relative_to(ROOT_DIR)} " )
Project root : C:\Projects\twitter-airline-analysis
Parquet source : data\processed\tweets.parquet
1. Load Processed Data & Train-Test Split
We keep raw string labels (airline_sentiment); scikit-learn encodes them internally.
Code
= pd.read_parquet(PARQUET_PATH)# Assert expected columns are present = {"clean_text" , "airline_sentiment" }= required_cols - set (df.columns)assert not missing, f"Missing columns: { missing} " # Sanity: no nulls in features / target assert df.clean_text.isna().sum () == 0 assert df.airline_sentiment.isna().sum () == 0 # Train / valid / test = 70 / 15 / 15 = train_test_split(= 0.30 ,= df.airline_sentiment,= 42 ,= train_test_split(= 0.50 ,= y_temp,= 42 ,print (f"Splits → train: { len (X_train)} valid: { len (X_valid)} test: { len (X_test)} "
Splits → train:10248 valid:2196 test:2196
2. Majority‑class reference
Majority‑class accuracy: 0.627 negative is correct 62.7 % of the time.)
Code
= y_train.value_counts(normalize= True ).max ()print (f"Majority‑class accuracy: { majority_acc:.3f} " )
Majority‑class accuracy: 0.627
3. TF‑IDF + Logistic Regression pipeline
Bi‑gram coverage, minimal regularisation tuning, and class_weight='balanced' to counter the 63 % negative skew.
Code
= Pipeline("tfidf" ,= (1 , 2 ),= 2 ,= 50_000 ,"clf" ,= 2_000 ,=- 1 ,= "balanced" ,
Pipeline(steps=[('tfidf',
TfidfVectorizer(max_features=50000, min_df=2,
ngram_range=(1, 2))),
('clf',
LogisticRegression(class_weight='balanced', max_iter=2000,
n_jobs=-1))]) In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
5. 5‑fold stratified CV on all data
Cross-Validated Macro F1: 0.749 ± 0.007
The low standard deviation indicates the baseline is stable across folds.
Code
= StratifiedKFold(n_splits= 5 , shuffle= True , random_state= 42 )= cross_val_score(= cv,= "f1_macro" ,=- 1 ,print (f"CV F1_macro = { cv_scores. mean():.3f} ± { cv_scores. std():.3f} " )
CV F1_macro = 0.749 ± 0.007
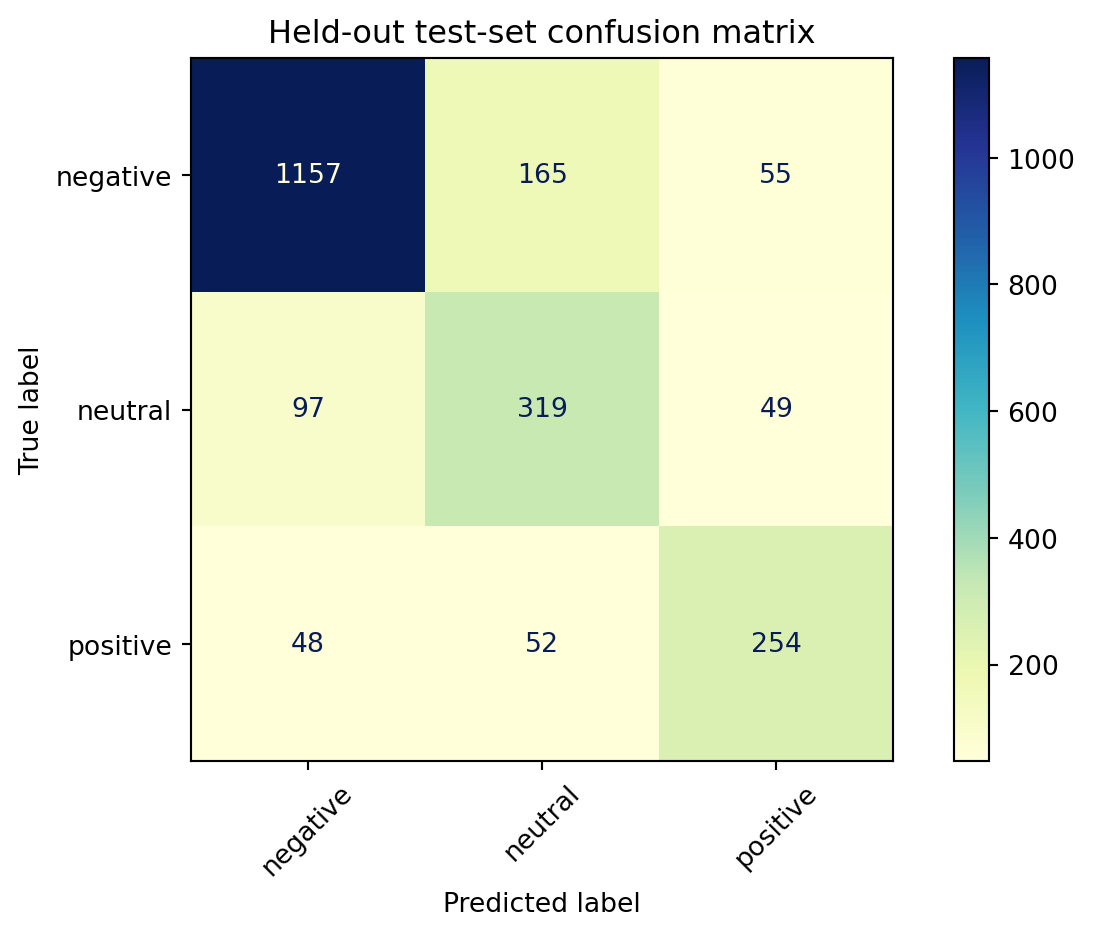
Held-Out Test Set Confusion Matrix
The confusion matrix visually confirms the model’s strengths and areas for improvement:
Negative Class: Excellent recall and precision.Neutral Class: Frequent confusion with both negative and positive classes indicates difficulty capturing neutrality.
(Matrix figure saved as reports/figs_04/conf_matrix.png.)
Code
# Held‑out predictions = pipe_lr.predict(X_test) # X_test comes from the earlier split cell = classification_report(= ["negative" , "neutral" , "positive" ],= True ,= 0 # tidy DataFrame, keep only precision/recall/f1 = (# classes as rows "negative" , "neutral" , "positive" , "weighted avg" ], # row order "precision" , "recall" , "f1-score" ]]= {"weighted avg" : "weighted" }) # shorter name round (3 )= pd.Series({"accuracy" : accuracy_score(y_test, y_pred),"weighted‑F1" : f1_score(y_test, y_pred, average= "weighted" )round (3 )print (" \n Overall:" , overall.to_dict())= ConfusionMatrixDisplay.from_predictions(= ["negative" , "neutral" , "positive" ],= "YlGnBu" , xticks_rotation= 45 , colorbar= True "Held‑out test‑set confusion matrix" )/ "conf_matrix.png" , dpi= 150 )
negative
0.889
0.840
0.864
neutral
0.595
0.686
0.637
positive
0.709
0.718
0.713
weighted
0.798
0.788
0.792
Overall: {'accuracy': 0.788, 'weighted‑F1': 0.792}
6. Persisted Artifacts
Model: models/logreg_tfidf.joblibCross-Validation Scores: models/cv_logreg.json
Code
= MODELS_DIR / "logreg_tfidf.joblib" = MODELS_DIR / "cv_logreg.json" print (f"Saved model → { MODEL_PATH. relative_to(ROOT_DIR)} " )with CV_PATH.open ("w" ) as fp:"f1_macro" : cv_scores.tolist()}, fp, indent= 2 )print (f"Saved CV scores → { CV_PATH. relative_to(ROOT_DIR)} " )
Saved model → models\logreg_tfidf.joblib
Saved CV scores → models\cv_logreg.json
7. Key Takeaway
Baseline (majority class) caps out at 62.7 % accuracy.
TF‑IDF + Logistic Regression lifts validation accuracy to 78.8 % and macro F1 to 0.74 .
5‑fold CV confirms robustness (0.749 ± 0.007 macro F1).
Confusion matrix shows excellent precision for the negative class but persistent confusion between neutral and both extremes.
With class‑weight balancing and bigram coverage, a classical model already delivers a +16 pp accuracy gain over the baseline—good enough for a production fallback while we prototype transformer models in Milestone 5.